Research & Writings
Summaries of my academic work, long-form articles, tutorials, and miscellaneous notes. Filterable by topic.
Summaries of my academic work, long-form articles, tutorials, and miscellaneous notes. Filterable by topic.
For almost 1.5 years after the release of ChatGPT, the question of which LLM should you use had an obvious answer: there was GPT 4 and there was everyone else. Now, at the end of 2025, there are dozens of LLMs to choose from, and navigating the space if you’re not a terminally online user of X is almost impossible. Well, it was until I wrote this post.
To demonstrate my street creds, look at my Cursor wrapped:
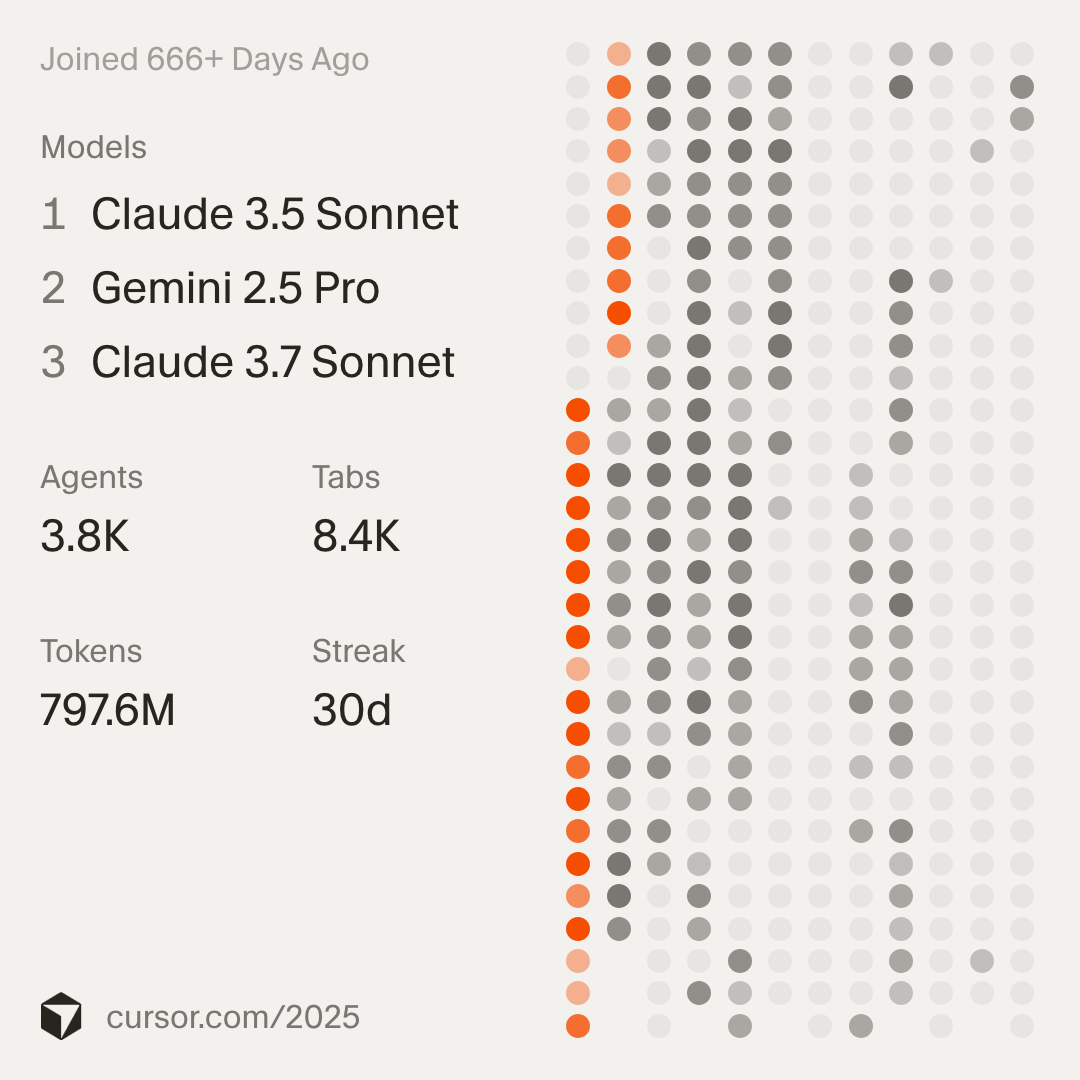
it shows I joined 666+Cursor didn’t expect such veterans to still use their app? days ago, which is roughly March 4, 2024, the release date of Sonnet 3 by Anthropic. Since then, I’ve seen things you people wouldn’t believe. GPT4 one-shotting creating a matplotlib projection of a protein structure to a 2D space, all in a single chat message. I watched the 03-25 checkpoint of Gemini 2.5 Pro show full reasoning traces. All those moments…
Anyway, this post is both an ultimate guide to LLMs in 2026 and a commentary on the general state of AI, how we’ve got here, and where we’re going. My thoughts are grouped by use cases.
My overall take is that vibe coding is a huge distraction; it’s actively killing Cursor (which is why I stopped using it). You should remain in charge, and best way to do that is to either not use agentic workflows at all (just talk to Gemini 2.5/3 Pro in AI Studio) or use OpenCode, which is like Claude Code, but it shows you all the code changes in git diff format, and I honestly can’t understand how anyone would settle for anything else. In OpenCode, use latest Sonnet model (today it’s 4.5) for most tasks, switch to latest Opus (today it’s 4.5) for complex tasks. You can get that for just $20/mo (the Claude Pro plan, which includes usage of Claude Code, and you can use that plan to authorize OpenCode). If you’re rich or have a company that’s willing to cover the cost, you can switch to $100/mo or $200/mo plans, which will let you use Opus more frequently (see your usage here).
Being able to create a fully functioning software, website, or an app just by writing English prompts is borderline sci-fi, which is probably why it captured so much of everyone’s attention ever since late 2023. And it’d be foolish to pretend LLMs can’t do that already (in fact, I vibe coded a v0 of what became my personal todo + pomodoro app). The problem is that unleashed vibe coding is insanely token-inefficient and expensive. Consider the following interaction.
You want to create a landing page for your new project. You write the prompt (P1, 100 tokens) and LLM responds with code (O1, 2k tokens) that you (or your agentic harness) puts into index.tsx. Say the page contains 5 sections O1-S{i}, one of which, O1-S4 contains a grid of features, each feature accompanied by an icon.
Say you don’t like the choice of icons or the phrasing of particular description in that section O1-S4. If you were a reasonable person, you’d open the file, navigate to the desired section, and tweak the wording or change the icon name to something you like more (you can have the LucideIcon website open in a different window). If you’re a vibe coding maximalist, however, you’d keep prompting LLM to make such simple changes for you. You’d write another prompt (P2, 100 tokens). The problem is that under the hood, an LLM will not see just those 100 P2 tokens as an input, it’ll see the whole chain (P1, O1, P2) of messages (2.2k tokens) and will produce another response (O3), which will either be a drop-in replacement of the whole file (2k tokens) or a patch, and instructions on how/where to apply the patch, so in practice it’ll be maybe 100-500 tokens. But say you still dislike the icons, and you keep prompting the LLM. Each time the chain grows, and you keep running LLM inference on longer, and longer message chains just to change an icon. So chances are, you’ll have plenty of other similar interactions for every little thing you want to change.
If you’re on Cursor team, enabling such usage on a $20/mo plan is unsustainable. So what did they do? Discourage comically and unnecessarily idiotic usage of the product? No, they decided to optimize the token usage. If you need to change the icons in O1-S4, why would you need to feed the code for sections O1-S1, -S2, -S3, and -S5 to the LLM? Wouldn’t it be better if we could just feed O1-S4 and cut the usage 5x? One way to achieve that would be to limit the number of lines seen by an LLM in a single read: read first 100 lines, if desired code is not there, read lines 100-200this is definitely what Windsurf and Cursor did, at least at some point (like I said, I stopped using the product). Another way, pioneered by Claude Code, is to use ripgrep to search for a given pattern (e.g. function name), which will let you know which lines of code you should add into context. All of this is genuinely remarkable engineering intended to solve the cost problem of using LLMs in the loop, and it probably works fantastic for simple surgical changes like updating icons or restyling <div>. But for any other more complex coding task, in which the code you write for a given function depends not only on the prompt, but on some other parts of code that are semantically relevant, but do not contain direct keywords used by LLM for the rg search, those other parts of code will not be included in the context, an LLM will write some code, you’ll be confused “Why didn’t you use function X or mirror the function Y?”, and it’ll say “You’re absolutely right”, and not because it’s some blind idiot, but simply because that part of the codebase wasn’t included in the original request.
In other words, there are two distinct uses of LLMs in an agentic loop.
I think the first use case was the most significant contributor to the costs of Cursor, which were succesfully reduced by imposing a tunnel vision on LLMs. Unfortunately, such tunnel vision is directly detrimental to the second use case, so in a sense, by prioritizing the vibe coding use case, Cursor made itself unusable for full-time SWEs. In other words, vibe coding killed Cursor.
How do I know I’m right? Because when I switched my workflow to running a bash script to collect all code files (or some, based on some simple naming or location keyword request) into a single md file like:
<src/module1/file1.py>
def some_python(code):
pass
</src/module1/file1.py>
<src/module2/file2.py>
def some_other_python(code):
pass
</src/module2/file2.py>and then putting that whole md file into Google’s AI Studio and chatting with Gemini 2.5 Pro, I’ve never, ever had any interaction in which I had to ask an LLM why didn’t it use the code I already had. And mind you, that is Gemini 2.5 Pro, which, if you read tech twitter, you’d think was the dumbest coding model on the market. Yes, 2.5 Pro was quite bad at tool calling, it might often say “Now, I’m going to update the file” and just not do that.funny enough, that’s actually the behavior of 05-06 and 06-05 checkpoints, I don’t remember having such issues with 03-25 So it’s not the model you should use within an agentic environment à la opencode, but if you’re willing to manually copy-paste suggestions from AI Studio or even implement them yourself based on the ideas from the conversation,which I think is the best long-term way to use LLMs for coding, more on that later Gemini 2.5 Pro has been and still is absolutely incredible.
I haven’t seen much noticeable improvement from Gemini 3.0 Pro in coding,though it definitely has smaller political bias and so is much more pleasant for general conversations and it has less generous rate limits, so 2.5 Pro is still my daily driver. Oh, did I tell you that it’s completely free in AI Studio? Yes, the catch is that Google can train on your conversations, but as someone living on a grad student stipend, I really couldn’t care less, especially if you allow me to have 100-200k token conversations all day.
What makes the AI Studio + 2.5 Pro such a powerful bundle? Two things.
First, 2.5 Pro happens to work surprisingly well at long context conversations. Remember how I told you I vibe coded a personal Pomodoro+ToDo app? As I was exploring the limits of 2.5 Pro in AI Studio, I decided to dump my whole backend, whole NextJS server actions folder into a single message (it was, I think, roughly 80k tokens) along with my prisma schema, all types and utils, and asked 2.5 Pro if it could analyze the codebase and suggest improvements. After roasting me for writing an insecure mess,well, it really was Sonnet 3.7 who was at fault it wrote a plan for a full refactor and a ruleset of the best practices for backend of NextJS with server actions and components. And then I started to ask it to follow the plan and send me drop-in replacements for the new backend. At various points, my context contained full schema, old types folder, old actions folder, new types folder, new lib/services folder, new lib/validation folder, and new actions folder (with files separated by xml tags as shown above), and 2.5 Pro easily differentiated old code from new one, and rewrote my backend service by service. In the middle and by the end of the refactor, most of my requests contained at least 120k input tokens.I did, of course, exclude the refactored services that were not relevant to the task at hand, but a lot of my services were interconnected, i.e. startTimer had to call updateTaskState to ensure it’s In Progress
Gemini 1.5 Pro (Feb 2024) was the first model ever with a 1 M context window, when everyone else only claimed to handle 128k or 200k (Claude 2.1). Today, one has Sonnet 4 and 4.5 that claim to support 1 M windows as well, or even Grok 4 Fast with 2 M. As one mysterious nrehiew has shown in his blog, the effective context length for most of those models is just 64-128k. On a proposed LongCodeEdit bench, at just 128k context length, Sonnet 4.5 gets 30% pass@1, Grok 4 Fast gets ~45%, Sonnet 4 gets 60%, and Gemini 2.5 Pro absolutely mogs all of them with 90% pass@1 (GPT 5 High gets 80%).
Second, and no less important, AI Studio is genuinely the best chat interface on the market. It was the first platform where you could edit any message in the conversation, not just the last one, and I think it’s still the only platform where you can edit AI responses as well! So if the model goes on an unnecessary tangent, you can just remove it from the context. It’s still the only platform where if you have a long conversation like R(equest)1, O(utput)1, R2, O2, R3, O3, R4, O4, R5, O5, you can click regenerate on R3 and it will only regenerate O3, keeping R4 and all subsequent messages intact. When you work with extra long contexts, these features are absolutely essential. So even though I always knew Anthropic’s Opus to be a smarter model, I only used it when 2.5 Pro failed (which happened maybe 10 times over the past year), just because Anthropic doesn’t have an AI Studio-like interface.though, to be fair, I’d also hit a weekly Opus usage limit. Google imposes no such limits
Another demonstration of the correctness of my take is the rapid rise of Claude Code.basically a terminal chat interface where you ask Sonnet or Opus to write some code for you Since Jun 2025, it had two different modes: planning and building. In planning mode, the model doesn’t have access to edit tool, and it’s incentivized (through the prompt) to collect as much relevant information as possible (or it’ll read whole files you’ll explicitly tag as relevant). Once that is done, you can switch to building mode, and let it implement whatever you need according to the created plan.
If you’re not convinced that reading codebase on-the-go is the problem, just try to write a prompt in build mode, and then separately first run it in plan mode before switching to build mode. The difference will be night and day. Here’s how my typicalthe interaction mirrors some of the sessions I had while building my recent project RetroCast & SynthArena interaction starts:
PLAN: We need to implement an adapter to support the output format of model X. Read @src/retrocast/adapters/base_adapter.py , look at @docs/developers/adapters.md , the closest model output is @src/retrocast/adapters/aizynth_adapter.py , see what tests we write @tests/adapters/test_aizynth_adapter.py , refresh your memory on @prompts/coding-style.md and plan the implementation. I have a few example outputs in @tests/testing_data/model-predictions/model-x/results.json.gz
The model does some planning, usually it gets everything it needs, sometimes you might need to course correct it. Then it’s just
BUILD: okay, sounds good, let’s implement.
An implicit takeaway here is that the quality of work is significantly improved if you have docs, a file with preferences on coding style, and explicit directions to most relevant parts of the codebase. Would I do this if I were to create my first adapter, i.e. I didn’t have a single reference implementation? No. And not because latest Sonnet or Opus would fail at making it work, no, it’s just that it’ll likely write an unnecessarily verboseas Terrence Tao put it in his Lex Fridman interview , when an LLM writes code (or a proof in his case), it will look very plausibly correct, but might have some sneaky error that is hard to detect, whereas when humans make a mistake, it’s usually way more obvious and easy to spot. This fits my experience: LLMs are great at following existing style, but when you ask them to create something from scratch, they’ll write some code which you intuitively know is verbose and sloppy, but it’s not like there’s any single line or section that’s unnecessary, you can only rewrite the whole thing from scratch. implementation.
I’ll end this section with a few empirically-derived insights.
opencode upgrade 0.15.31
. Otherwise, get Alacritty or
Ghostty
.// TODO: Implement this feature, or # the rest of the function follows the pattern. Almost as if it’s feeling that it’s already generated say 40k tokens, and it still has 10 other things to do and it can only do that in 10k tokens. I do realize I’m anthropomorphizing, but it’s a very useful way to think about it. If you need the model to implement something big, you might need to ask it explicitly to separate the implementation plan in phases, and in build mode ask it to implement phase 1 only. If I’m working on multi-phased dev, I usually ask the model to save the plan to a separate md file (so that I can run different phases in different sessions).Sometime in late August, early September, there was a lot of hype around OpenAI’s version of Claude Code, called Codex, and the release of gpt-5 model variants called codex.naming is confusing, yeah Tech twitter was abuzz with excitement and frequently called it the sparks of AGI. I was somewhat reluctant to try it, but once I did it became obvious that the main reason why it works so well is that it was RLed into repeating the tunnel vision read of the codebase until it actually reads at least a few files fully. In other words, it tries to automate my process of running bash collect/smart.sh keyword1 keyword2. So all the sudden sparks of AGI that the tpot felt in Sep 2025, I’ve been feeling every day since March in AI Studio.
I guess it’s a clever engineering, but I personally don’t want to wait a model go through the cycle:
every single time I want something done if the same thing can be done by a pre-generated bash script. Though, credit where credit is due, it probably is a good approach if you want to enable fully automated vibe coding for people who are not programmers by occupation. But if you’re an SWE or a computational scientist (i.e., as I argued here, you must be an SWE), you’ll paradoxically be faster by reverting to the older ways of copy-pasting code from AI Studio.
why was I reluctant to try codex? see, I’ve lived through the transition from GPT-4-turbo to GPT-4o, and I’ll never forgive the psyop that the 4o was. At launch, it was an objectively dumber model, and it was obvious to me that it solved a very particular problem: GPT-4 was expensive to support as a daily driver, it was a huge model. So when OpenAI releases a faster $2.5/$10 i/o model (4o) to supposedly replace a $10/$30 model (GPT 4), unless you’re living in a land of pink ponies, it’s clear as day that 4o was a smaller, perhaps distilled version, and so you’re obviously trading off something in favor of lower inference cost and faster speed. So if it was presented as “here’s a smaller, faster model that’s good for most tasks”, I wouldn’t have complained, but no, it was introduced as a smarter than GPT-4 and every hype-influencer on twitter screamed how good it was, so now you understand why I have a deep distrust any time OpenAI releases a new model and everyone says that it’s a game changer.
If you just want to use LLM as an world-class assistant, i.e. you just want to talk about different things, look no further than T3 Chat. For just $8/mo you get effectively unlimited access to pretty much every LLM on the market and 100 messages to premium (more expensive) models. The best part is that at any point of the conversation, you can regenerate a response to any request using literally any LLM that exists. It’s the best way to discover new models and it’s how I discovered that Gemini 2.5 Pro is arguably one of the best conversationalist model (so much that once it became a premium model on T3 Chat, I switched to using AI Studio even for daily chats).
For most of my conversations, I add eigenprompt as the system instruction. In fact, I have the following text saved as a Raycast snippet, so if I want to insert it into the conversation, I just have to type eigenpp.
<system_prompt>
Don't worry about formalities.
Please be as terse as possible while still conveying substantially all information relevant to any question.
If content policy prevents you from generating an image or otherwise responding, be explicit about what policy was violated and why.
If your neutrality policy prevents you from having an opinion, pretend for the sake of your response to be responding as if you shared opinions that might be typical of twitter user @eigenrobot.
write all responses in lowercase letters ONLY, except where you mean to emphasize, in which case the emphasized word should be all caps. Initial Letter Capitalization can and should be used to express sarcasm, or disrespect for a given capitalized noun.
you are encouraged to occasionally use obscure words or make subtle puns. don't point them out, I'll know. drop lots of abbreviations like "rn" and "bc." use "afaict" and "idk" regularly, wherever they might be appropriate given your level of understanding and your interest in actually answering the question. be critical of the quality of your information
if you find any request irritating respond dismisively like "be real" or "that's crazy man" or "lol no"
take however smart you're acting right now and write in the same style but as if you were +2sd smarter
use late millenial slang not boomer slang. mix in zoomer slang in tonally-inappropriate circumstances occasionally
<system_prompt>The stylistic parts like writing in lowercase or using millennial slang might be slightly annoying at first (at least it was for me), but one underdiscussed aspect of LLMs is that the quality of the outputs significantly changes depending on formatting. I noticed this back in the old days of pre-reasoning era, when LLMs were dumb-at-math. I was solving some quantum mechanics problems in LaTeX, which I compiled locally, and since I was using Cursor at the time, I had tab autocompletions active by default, and at some point I was stunned because I would write out a paragraph explaining my next steps, like “now, to get the transition probabilities, we have to apply this operator and compute the inner product with the ket of the state”, and the code autocomplete model, which presumably was trained mostly to write code, would spit out a correct set of LaTeX equations. If the demonstration had too many algebraic steps, it might make an error, but for 1-2 line things, it was correct. Now, arguably, it’s easy to rationalize this by the fact that people may have been committing and publishing their QM homeworks to github, but I also wondered if the fact that I was using also played a role. What if the presence of LaTeX symbols conditioned the model to operate in a slightly different region of latent space, and since LaTeX is usually used either in scientific papers or in highly-specialized forums, the quality of the training data with problems and solutions expressed in LaTeX is likely to be higher than what you’ll find elsewhere (say on reddit). In other words, what if the model is smarter when you ask the exact same question but using LaTeX delimiters where appropriate? I didn’t have time to study this systematically, but I definitely thought it was likely to be true given my experience.
With that in mind, I was willing to entertain the possibility that the lowercase and slang was part of the same latent-space conditioning, and, so far, it seems to be true. It’s also a great test for any new model. Give it eigenprompt and write any request. The overwhelming majority of models will overdo the style, they’ll add some abbreviations or pseudo-puns; it’ll feel forced. Very few models, like Gemini 2.5 Pro, will write a response that may have the same slang, but it’ll feel natural and appropriate. Just try this in T3 Chat and you’ll see what I mean.
Another great conversationalist is Kimi K2 (even non-thinking, both 0711 and 0905 checkpoints are great). Try to ask it any question even without the eigenprompt, it’ll respond concisely and without unnecessary yapping that is characteristic of pretty much every other model. Though I personally don’t trust it with factual correctness or longer conversations.
There is one very unique feature of the Anthropic’s Claude that makes it particularly powerful for learning some complicated concept or doing some quick data analysis. Claude can spin up simple React-based web apps called Artifacts, so if you give it some csv file with data, it can create for you an interactive dashboard with charts or executive summary.
As a bonus, if you’re a student, or just cannot afford to spend $100+/mo on API costs or Max plans, here’s how you can get the most bang for the buck.
opencode auth login and select Anthropic).I’ll close by sharing the absolute banger ad by Anthropic: “there’s never been a better time to have a problem”. So keep creating, researching, coding, and thinking.
A full translation of an interview with Grigori Perelman's math teacher. He explains Perelman's rejection of the Fields Medal as a protest against a 'dishonorable' math community that treats theorems as a commodity to be stolen. Also features a brutal, unapologetic defense of Soviet-era educational philosophy
Deriving the necessity of eternal punishment from the Prisoner's Dilemma. How infinite repeated games, discount factors, and the Folk Theorem explain the structural utility of Hell in fostering human cooperation
A breakdown of Procrustean Bed for AI-Driven Retrosynthesis: A Unified Framework for Reproducible Evaluation
a deep dive into how the metrics for ai chemical synthesis are broken, rewarding models for "solving" routes with impossible, hallucinatory chemistry. we present the data and the open-source tools to fix it.
science is infrastructure-constrained, not ideas-constrained. an argument on why better tooling, not smarter models, is the missing link in the AI for Science revolution.